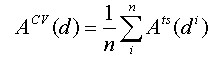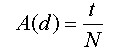
You think that it could have understanding, in
former explanation, the taxonomic model by the decision tree some kind
of ones. Next it will keep advancing story concerning the
precision of the model. With formation of the taxonomic model,
theprecision(Accuracy) becomes
very important. Constructing the taxonomic model, if it fits the
unknown data, "it comes off" always and with is troubled.
The precision in the taxonomic model, when all case (with
example of golf 14 cases) fitting in the model, being something which
is displayed in the case of some case is just classified, ratio it
does. Because with example of golf, the case of 14 cases
everything is classified just, precision becomes 100%.
But, "the answer", namely the oak which does golf there was no
data of these 14 cases, but because it is the data which understands,
it is natural to be able to draw up the model which can classify only
those data accurately. Whether or not problem the model which
was made there confronting also the unknown data, is accurate, is.
As for this, it is possible to compare to preparatory study for
examination. If problem of the reference "while looking at the
answer," if it keeps solving, it is the problem which has been
recorded before the reference, with any kind of problem 100% it
reaches the point where you can correctly interpret, probably will be.
Therefore with saying, the test of the production (as for the
answer you see and there is no �s! ! ) With you can
obtain the good result, with it does not limit.
Then, the necessity presuming the precision of the model for the
unknown data with a some method comes arising. If you refer to
preparatory study for examination, the standard that "as for you as
for the probability which it can pass to 00 universities it is 60%",
becomes necessary. Presumptionof precision
of the model(Accuracy estimation) there are
the next three methods largely.
If as for this with very simple thought, you refer to the above-mentioned example, the decision tree (d) with the case which constructed that model to the model which is displayed, (it makes N case) for the second time to apply, it is the method probably designating as estimator of model precision, it sets, about which it is classified (makes t case accurately) that way. The precision A due to alternative presumption method (d) it is displayed with the following formula.
But because this uses the data which was used in construction of the model that way for precision presumption, you can say that very optimistic presumption method (it reaches high precision) is, probably will be.
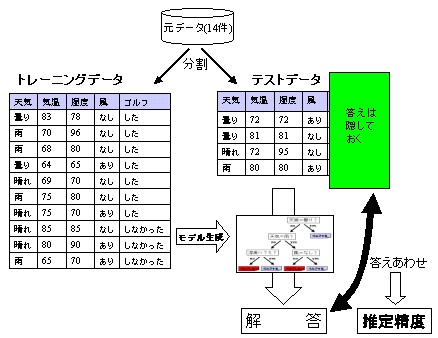
Then, the method of preparing the data in order to
construct the model and the data in order to presume the precision
beforehand separately is test sample method. First divides the
data of the basis, to random (as for ratio of division, the test data
1/3, it is general in two data which are called the training data and
the test data) to designate the training data as 2/3. In
addition, also both data, it is desired that it is the kind of data
which represents the original data. For example, the case which
"does golf" is not completely included in
����������Ǭ������ǻ, only the case whose air temperature is
high being included, it is problem. Then it can use the
technique whichusually "the stratification(Stratification) " with is called. In
order the occasion where sampling is done from the original data,
distribution of value of each attribute, to become similar to the
distribution of the original data, being to sample, it does.
As for formation of the model it draws up the training data (the
answer equipped data) of making use, fits the test data in that model.
And the taxonomic precision in the test data, is designated as
precision of that model, (rough sketch reference). If you refer
to preparatory study for examination, it hits to verifying without
looking at the answer, solving, seeing, about which you correctly
interpret several problems of the reference.
When it designates the entire number of casesof the test dataas N ts,
among those, fits in the model and it designates the number of
cases which really is correct answeras
t ts, the presumption precision A ts due to
test samplemethod(d) it is
displayed with the next formula.
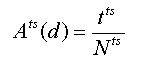
Test sample method, when sufficiently there is a
data quantity, does not become problem, but when the data quantity is
small, the possibility big error occurring in presumption precision
with the method of choosing the test data, becomes high. In that
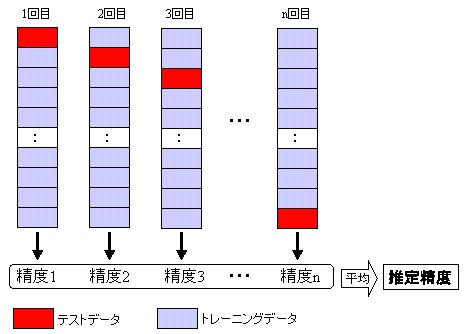
kind of case, the intersection verification method which is explained
here is used. With this method, it can use value 10 - 20 the
original data n is divided into block first (usually as n). At
that time, the number of cases which is allotted to each block that
tries becomes same. In addition also each block is desired,
being stratified.
And first, the first block the test data and other blocks as a
training data, construction of the model and calculation of precision
are done. It designates second blocks as the test data
designates other blocks as the training data, keeps doing model
construction next. This kind of procedure the n time will be
repeated, being something which average of the precision which was
calculated with each time, will be designated as presumption precision
of the model, it does. You think as becoming aware, but as for
trial of each time, it is found that it is the test sample method
ratio of the test data due to 1/n.
When intersection verification method is used, all cases, as for
one time are chosen happen to see still and as the test data, come to
the point of constructing the model making use of the training data of
number of cases of n - 1 times that the upper original data, the
little data being, presumption error decreases.
When the decision tree which was constructed to the n time eye
with the figure underis designatedas d n, the precisionis doneA ts(d
n) with, it is given with the presumption precision A
cv(d) following system due
to intersection official approval.